
PlatoNeRF, created by MIT and Meta, employs multibounce lidar and machine learning to enable autonomous vehicles to detect hidden obstacles. This innovative technique, which also assists in AR/VR and robotics, uses shadows to generate precise 3D reconstructions of environments.
Researchers leverage shadows to model 3D scenes, including objects blocked from view.
This technique could lead to safer autonomous vehicles, more efficient AR/VR headsets, or faster warehouse robots.
Imagine driving through a tunnel in an autonomous vehicle, but unbeknownst to you, a crash has stopped traffic up ahead. Normally, you’d need to rely on the car in front of you to know you should start braking. But what if your vehicle could see around the car ahead and apply the brakes even sooner?
Researchers from
They have introduced a method that creates physically accurate, 3D models of an entire scene, including areas blocked from view, using images from a single camera position. Their technique uses shadows to determine what lies in obstructed portions of the scene.
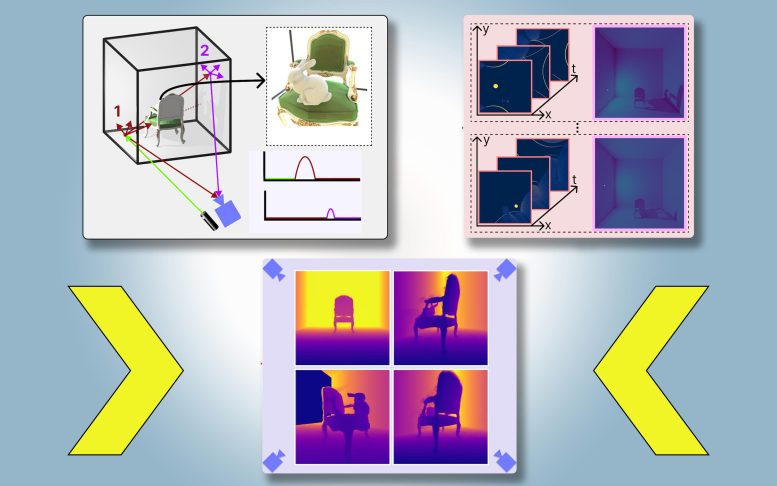
Plato-NeRF is a computer vision system that combines lidar measurements with machine learning to reconstruct a 3D scene, including hidden objects, from only one camera view by exploiting shadows. Here, the system accurately models the rabbit in the chair, even though that rabbit is blocked from view. Credit: Courtesy of the researchers, edited by MIT News
They call their approach PlatoNeRF, based on Plato’s allegory of the cave, a passage from the Greek philosopher’s “Republic” in which prisoners chained in a cave discern the reality of the outside world based on shadows cast on the cave wall.
By combining lidar (light detection and ranging) technology with SciTechDaily