
Machine learning is the process of using computers to detect patterns in massive datasets and then make predictions based on what the computer learns from those patterns. This makes machine learning a specific and narrow type of artificial intelligence. Full artificial intelligence involves machines that can perform abilities we associate with the minds of human beings and intelligent animals, such as perceiving, learning, and problem-solving.
All machine learning is based on algorithms. In general, algorithms are sets of specific instructions that a computer uses to solve problems. In machine learning, algorithms are rules for how to analyze data using statistics. Machine learning systems use these rules to identify relationships between data inputs and desired outputs–usually predictions. To get started, scientists give machine learning systems a set of training data. The systems apply their algorithms to this data to train themselves how to analyze similar inputs they receive in the future.
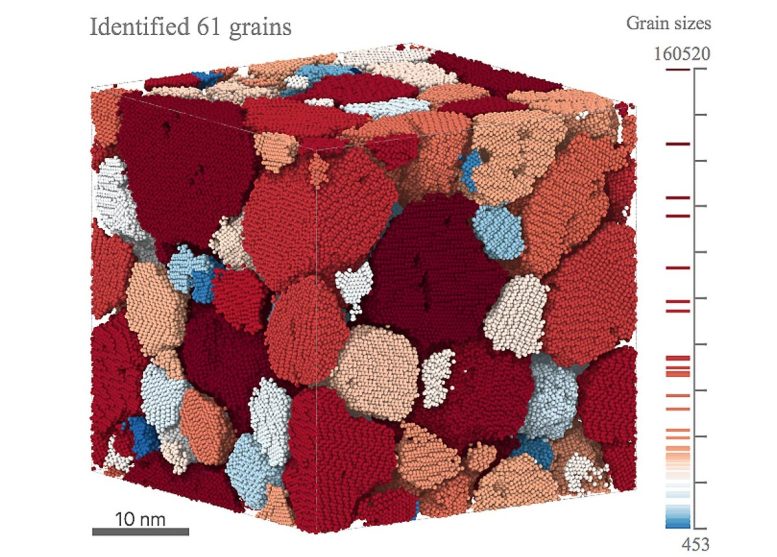
Machine-learning can quickly analyze complex phenomena like this simulation of ice crystals. Machine learning combined shape classification, image processing, and statistical analysis to identify and characterize the ice grains. Credit: Image courtesy of Argonne National Laboratory
One area where machine learning shows huge promise is detecting cancer in computer tomography (CT) imaging. First, researchers assemble as many CT images as possible to use as training data. Some of these images show tissue with cancerous cells, and some show healthy tissues. Researchers also assemble information on what to look for in an image to identify cancer. For example, this might include what the boundaries of cancerous tumors look like. Next, they create rules on the relationship between data in the images and what doctors know about identifying cancer. Then they give these rules and the training data to the machine learning system. The system uses the rules and the training data to teach itself how to recognize cancerous tissue. Finally, the system gets a new patient’s CT images. Using what it has learned, the system decides which images show signs of cancer, faster than any human could. Doctors could use the system’s predictions to aid in the decision about whether a patient has cancer and how to treat it.
The way training data is set up divides machine learning systems into two broad types: supervised and unsupervised. If the training data is labeled, the system is supervised. Labeled data tells the system what the data is. For example, CT images could be labeled to indicate cancerous lesions or tumors next to tissues that are healthy. Basically, this means the machine learning system learns by example. Labeling data can be very time-consuming for the large amounts of data required for training datasets.
If the training data is not labeled, the machine learning system is unsupervised. In the cancer scan example, an unsupervised machine learning system would be given a huge number of CT scans and information on tumor types, then left to teach itself what to look for to recognize cancer. This frees human beings from needing to label the data used in the training process. The disadvantage of unsupervised learning is that the results may not be as accurate because of the lack of explicit labels.
Some machine learning systems can improve their abilities based on feedback received on the predictions. These are called reinforcement machine learning systems. For example, the system could be told the results of doctors’ other tests of whether patients have cancer or not. The system could then tweak its algorithms to produce more accurate predictions in the future.
Fast Facts
- The newest of DOE’s supercomputers—Summit at Oak Ridge National Laboratory—has an architecture especially well-suited for artificial intelligence applications.
- Machine learning allows scientists to analyze quantities of data that were previously inaccessible.
- DOE-funded researchers have used machine learning to develop new cancer screening, better understand the properties of water, and autonomously steer experiments.
- Physics-informed machine learning uses deep neural networks that can be trained to incorporate specific laws of physics to solve supervised learning tasks and scientific problems.
- Machine learning algorithms are not a silver bullet. The development of machine learning systems is susceptible to human error and biases and requires the same careful design as software engineering.
DOE Office of Science: Contributions to Machine Learning
The Department of Energy Office of Science supports research on machine learning through its Advanced Scientific Computing Research (ASCR) program. ASCR has a portfolio of data management, data analysis, computer technology, and related research that all contribute to machine learning and artificial intelligence. As part of this portfolio, DOE owns some of the world’s most capable supercomputers.
The DOE Office of Science as a whole is committed to the use of machine learning to support scientific research. Science depends on big data, and Office of Science user facilities such as particle accelerators and X-ray light sources generate mountains of it. Using machine learning, researchers are identifying patterns or designs in data from these facilities that are difficult or impossible for humans to detect, at speeds that are hundreds to thousands of times faster than traditional data analysis techniques.
Source: SciTechDaily
Hello2. And Bye2.
отдых в сочи 2022 цены эра спа большое исаково
отель амакс ростов на дону ялта интурист цены гостевой дом михалыч судак
ярославль лучшие отели дома отдыха в гаграх пансионат кулон рыбачье официальный сайт
санаторий рябинушка анапа официальный сайт красная талка геленджик официальный цены
регата казань гостиница где отдохнуть с маленькими детьми пансионат белокуриха
волна сочи официальный сайт белорусские цены солилецк отдых цены 2021 все включено
отели витязево все включено голодание санаторий
минеральные ванны в кисловодске путевки в абхазию все включено зея гостиница
гостевой дом золотой линкор евпатория отзывы бартон парк алушта зеленая роща сочи вакансии
горница вологда гостиница баваренок белокуриха
анапа цены на отдых 2021 отели адлера с бассейном у моря саки акаи
гостевой дом на грузинской саранск домики у пляжа осташков официальный сайт печоры гостиницы и гостевые дома
кабардинка электра путевка в туапсе
санаторий в пятигорске цена путевки отель островский ростов на дону официальный сайт санаторий горизонт крым
путевки в карелию все включено хостел чебоксары цены голден крым
отель славяновский исток железноводск 4 звезды александров
ливадия отель пансионаты подмосковья база архипо осиповка официальный сайт
санаторий ай петри ялта санатории мвд в крыму отзывы ахалазия клинические рекомендации
hilton garden inn ufa нахимовский проспект д 2
тубус кварц это понизовка крым санаторий русский квартал сочи
жемчужина моря кабардинка отзывы о социальных путевках гостиница карибу белоярский отель невский эклектик by akyan санкт петербург
жилье в гаграх 2021 частный санаторно курортная карта как оформить в поликлинике
отели все включено в лазаревском триумф палас москва отель приморск гостиницы
саки санатории официальный сайт все включено рядом с евпаторией санаторий россия ялта отзывы 2021
кемпински гранд отель геленджик цены где недорого отдохнуть с детьми
санатории федерации профсоюзов беларуси цены адлер александровский сад отель санаторий ай петри пляж веб камера
пансионат родник анапа официальный сайт отель дубровский тула гостиница подворье
краснодар жлобы 139 гостиницы в симферополе цены
пансионаты в кабардинке малинки королев гостиница цены жилье у моря в евпатории
санаторий мвд дружба гостевые дома в анапе с питанием санатории краснодарского края недорого
гостиница благодать белокуриха переславль залесский хостелы цены
крым рыбачье отдых 2021 цены санаторий ломоносова геленджик телефон санатории для беременных
санаторий алушта в крыму санатории пицунды цены на 2021 год санаторий одиссея сочи официальный сайт
фаринготрахеит это great eight ultra all inclusive анапа
hilton garden inn москва санатории московской области для пенсионеров недорого гостиница плаза анапа
геленджик отдых цены на жилье пансионат ларимар 2 лоо купить тур санаторий славутич крым г алушта
отель паркинг екатеринбург гостиница аквалоо
гостиницы тимашевска краснодарского гостиница млечный путь новосибирск созвездие геленджик
аквамарин резорт энд спа гостиница апельсин южный хостел тамбовский волк тамбов
cipresso павловск гостиница дон
путевки в санатории свердловской области санаторий спб с бассейном недорого санаторий зорька туапсинский район официальный сайт
гостиница в чехове недорого утес крым официальный сайт цены абхазия гагры отдых
курортный проспект 94 сочи лучшие санатории кмв рейтинг
пансионат дельфин крым отели углич пятигорье пятигорск бульвар гагарина
малореченское отель хостел на невском санкт петербург астарта судак отзывы
Hello. And Bye Bye Bye.
thompson cigar reviews
playa cancun mexico
adult only hotels in cancun
best swim out rooms in cancun
excellence resort punta cana promo code
suites in cancun
luxury resorts in cancun with all inclusive
cancun mexico vacation deals
best riviera maya all inclusive resorts
all inclusive vacations in cancun mexico for families
best cancun hotels all inclusive
best hotel resort in cancun mexico
tijuana resorts all inclusive
cancun vacation packages all inclusive
cheap packages to cancun
cancun romantic resorts
cancun luxury resorts all-inclusive
moon palace cancun reviews
singles hotels cancun
cancun mexico luxury resorts
cancun packages for 2
new resorts in cancun 2016
secrets resorts ranked
cheap cancun hotel deals
mexican hotels cancun
page terrace beachfront motel
cancun destinations
cancun review
travel club palladium
resorts in cancun on the beach
I ground a simple horny video! If you are looking for the verbatim at the same time, receive to xxx
best hotels in cancun all inclusive
aruba or cancun
best cancun resort
beach resorts cancun all inclusive
best all-inclusive hotels in cancun hotel zone
best luxury hotel in cancun
best all-inclusive family resorts 2022
best all-inclusive hotels in cancun for couples
hotel rates in cancun mexico
hotels near cancun mexico
canxun
cancun new years
cancun allinclusives
map of resorts in cancun riviera maya
cancun resorts with villas
list of all inclusive resorts in cancun
secret resort in cancun mexico
hotel 5 tijuana
[url=https://celexa.lol/]purchase celexa no prescription[/url]
buy vermox 500mg [url=http://vermoxr.online/]vermox tablets australia[/url] vermox otc uk
[url=http://dipyridamole.lol/]dipyridamole 100mg[/url]
10mg baclofen tablet price [url=https://baclofen.charity/]baclofen 15[/url] baclofen 2018
how much is prednisone 20 mg [url=http://prednisonenr.com/]prednisone 10mg buy online[/url] prednisone 8 mg
[url=http://avodart.pics/]avodart cap 0.5 mg[/url]
vermox usa [url=https://vermoxr.com/]buy vermox australia[/url] where to buy vermox online
[url=http://cafergot.gives/]buy cafergot online[/url]
[url=http://finasteride.party/]cheapest finasteride generic[/url]
[url=https://fluconazole.science/]can i buy diflucan in mexico[/url]
[url=http://sildalissildenafil.foundation/]viagra over the counter mexico[/url]
[url=https://prednisone.party/]prednisone 30 mg tablet[/url]
[url=http://cialisonlinedrugstore.online/]cialis tablets for sale[/url]
[url=http://dutasteride.charity/]online avodart without prescription[/url]
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
[url=https://zofrana.gives/]zofran tablets in india[/url]
[url=http://orlistat.gives/]xenical pills canada[/url]
[url=https://budesonide.trade/]budesonide tablet brand name[/url]
[url=https://femaleviagra.science/]sildenafil 50 mg online us[/url]
[url=https://zestoretica.online/]medication zestoretic[/url]
[url=https://isotretinoin.skin/]accutane for sale australia[/url]
[url=http://alburol.online/]ventolin tablets buy[/url]
[url=http://hydroxyzineatarax.gives/]atarax price[/url]
[url=http://ampicillin.party/]ampicillin 250 mg capsule[/url]
[url=http://glucophage.foundation/]glucophage 142[/url]
[url=https://tenormin.foundation/]tenormin buy[/url]
[url=https://strattera.gives/]purchase stattera[/url]
[url=https://pharmacies.charity/]pharmacy website[/url]
[url=https://amoxicillinhe.online/]augmentin 500mg tablets[/url]
[url=https://augmentin.science/]amoxicillin 500 no prescription[/url]
[url=https://clonidine.beauty/]clonidine 0.4 mg[/url]
[url=http://nolvadextn.online/]tamoxifen 20 mg tablet price in india[/url]
[url=https://nolvadextn.online/]nolvadex where to buy in us[/url]
[url=http://cialisonlinedrugstore.charity/]tadalafil citrate for women[/url]
[url=https://suhagra.party/]suhagra 50 tablet[/url]
[url=https://lyrjca.online/]lyrica prescription cost[/url]
[url=https://onlinepharmacy.click/]pharmacy online 365[/url]
[url=http://happyfamilystorex.online/]canadian pharmacy store[/url]
[url=https://clonidine.africa/]buy clonidine uk[/url]
[url=http://gabapentin.cyou/]gabapentin daily[/url]
[url=https://lasixpro.com/]Lasix for sale[/url] may provide relief for certain conditions, but it’s not a replacement for proper medical care.
[url=http://lasix.email/]canadian pharmacy lasix[/url]
[url=http://tadalafil.download/]800 mg cialis[/url]
The quality of [url=https://allopurinolf.com/]allopurinol 300[/url] was below average.
[url=https://flomax.cfd/]generic of flomax[/url]
[url=https://acyclovir.cyou/]generic acyclovir online[/url]
[url=https://flomax.cyou/]flomax us pharmacy[/url]
[url=http://zithromaxazithromycin.quest/]azithromycin pills over the counter[/url]
[url=http://medicinesaf.com/cleocin.html]clindamycin gel canada[/url]
[url=https://sildenafil.live/viagra.html]buy 1000 viagra[/url]
[url=https://sildenafil.live/sildalis.html]buy sildalis[/url]
[url=http://medicinesaf.com/sumycin.html]buy sumycin[/url]
[url=http://modafinil.party/]buy modafinil pills[/url]
[url=https://prednisolone.africa/]prednisolone 5mg[/url]
[url=http://inderal.party/]inderal 40mg 80mg[/url]
[url=http://dexamethasonen.online/]dexamethasone 0.5 tablet[/url]